지난글에 이어서 정리해봄
4. 데이터 인덱싱, 슬라이싱
인덱싱은 리스트에서도 많이 다룬 개념이다. 배열이던 리스트던 요소값에 주소가 할당되는데 그 주소값을 이용해 요소값에 접근하는것을 인덱싱(indexing)이라고 한다. 넘파이 배열의 인덱싱방식은 리스트와 유사하다.
import numpy as np
array_a=np.array([[1,2,3],[4,5,6]],int)
array_a[0][2]위 배열에서 숫자 3을 인덱싱하려면 위와같이 할수있다. 리스트에서의 인덱싱방식과 동일하게 배열명[상위랭크1 인덱스][상위랭크2 인덱스].... 이런식으로 하면된다. 여기서 상위랭크라는것은 .. 가장 높은차원의 위치값부터 인덱싱하는것을 의미한다. 예를들어 Rank3의 3차원 텐서의경우 [평면의 인덱스][행 인덱스][열 인덱스] 순으로 간다. 좀더 간단하게 그냥, 바깥쪽에있는 대괄호부터 인덱싱해준다고 이해하면 쉽다.
아니면 인덱싱을 배열명[상위랭크1 인덱스, 상위랭크2 인덱스,....] 와 같이 하나의 대괄호안에 콤마로 구분해도된다.
인덱싱은 요소값의 주소로 해당 요소값을 찾는행위라면 슬라이싱은 인덱싱을 이용해 리스트의 일부를 잘라내서 (슬라이싱) 반환하는 기법이다.
import numpy as np
array_a=np.array([[1,2,3],[4,5,6]],int)
array_a[:,2:]리스트 일부만 잘라낸다는게 별다른 함수를 쓰는건아니고 인덱싱 기반인데, 한꺼번에 여러개의 요소를 불러내는것이다.
matlab과 마찬가지로 파이썬에서도 : 는 범위를 지정해서 해당범위내 모든 요소를 반환한다. 아무런 지정도없이 : 만 쓰면 모든요소를 다 반환하고, 2 : 는 2 인덱스를 포함해 인덱스 뒤 모든 요소를 반환, : 2는 2인덱스를 포함해 인덱스 앞 모든 요소를 반환한다. 널리쓰이는 기법이지만 그냥 '슬라이싱'이라는 명칭만 붙인 느낌이다. 별거아니다.
위 코드를 출력한결과는 아래와같다.

'2 인덱스 이상의 열의 모든 행을 반환한것'과 같은 의미이다. 슬라이싱을 이용해 전체 데이터셋에서 특정부분만 따로 빼서 사용할수있다.
5. 서로다른 배열을 합치기 (vstack, hstack)
배열을 잘랐으므로 합칠수도 있지 않을까? 다만 서로다른 두 배열을 합칠땐 넘파이 내장함수를 따로 써줘야한다. vstack와 hstack 함수인데 이름만봐도 느낌이 온다. v는 vertical.. 배열을 수직으로 결합하고 h는 horizontal.. 배열을 수평으로 결합하는 의미이다.
import numpy as np
array_1 = np.array([1,2,3],int)
array_2 = np.array([4,5,6],int)
print(np.vstack((array_1,array_2)))
print(np.hstack((array_1,array_2)))vstack과 hstack 결과를 print문에 넣어 출력결과를 비교해보자. 두 배열을 정의한후 np.vstack((배열명1, 배열명2)) 혹은 np.hstack((배열명1, 배열명2))와 같이 입력한다.

줄바꿈이 한번밖에 안되서 보기에 헷갈릴수있지만 위 2줄의 결과가 vstack, 아래줄의 결과가 hstack이다. 두 배열을 수직, 수평으로 쌓을수있다.

여기선 1행 3열로 동일한 구조의 두 배열을 합쳤지만 구조가 꼭 동일하지않아도 된다. vstack은 위아래로 쌓으므로 열의 갯수만 동일하면되고, hstack은 수평으로 합치므로 행의 갯수만 동일하면된다.
6. 배열간의 사칙연산
생성된 배열간 사칙연산도 가능하다.
import numpy as np
array_1 = np.array([[1,2,3],[4,5,6]],int)
array_2 = np.array([[7,8,9],[10,11,12]],int)
print(array_1+array_2)
print(array_1-array_2)두 배열의 덧셈, 뺄셈 결과를 확인해보자. 두 배열을 생성해서 배열명1+배열명2 혹은 배열명1-배열명2 으로 구할수있다.

출력결과를 보면 배열의 요소 합,차가 계산된것을 볼수있다. 여기까진 끄덕끄덕. 중요한건 곱과 나눗셈이다. 행렬곱으로 계산이 될까?
import numpy as np
array_1 = np.array([[1,2,3],[4,5,6]],int)
array_2 = np.array([[7,8,9],[10,11,12]],int)
print(array_1*array_2)
print(array_1/array_2)연산자만 곱과 나누기 연산자로 바꿔서 출력해보자.

그냥 곱을해도 요소별 곱/나누기 계산이 된다. 행렬곱이 아닌 요소별 곱이 된걸보면 데이터 가공 측면에서는 오히려 더 편할지도? 행렬곱계산은 matlab으로 하지 뭐...
7. 인덱스 반환 함수(where, argsort, argmin, argmax)
인덱스 반환함수는 데이터 가공/분류할때 꽤 유용하게쓰인다. 데이터셋(배열)에서 5를 초과하는 값들의 인덱스를 반환해보자.
import numpy as np
array_1 = np.array([[[1,2,3],[7,8,9]],[[1,1,6],[10,11,9]]],int)
np.where(array_1>5)where함수는 조건을 부과해 참인값들에 대한 인덱스를 반환한다. np.where(조건)형식으로 사용하며 조건을 기술할때는 array_1>5와 같이 배열명 조건 형식으로 기술한다. 위의 코드를 실행한 결과값은 아래와같다.

3개의 array가 출력되는데 각 array의 열값을 합치면 조건을 만족하는 value의 index이다. 예를들어 0번열인 0,1,0은 7의 위치값이다. 1번열인 0,1,1은 8의 위치값이다. 배열이 3차원 텐서이기때문에 결과값인 위치 array도 3개 출력된다.
배열내 value의 값이 작은순서대로 인덱스를 반환할수있다. 무슨말이냐면, 작은값 순서대로 인덱스를 0부터 할당하는것이다. 기존 정렬알고리즘을 사용해도 되지만 넘파이에선 자체 내장함수로 최솟값부터 오름차순으로 최댓값까지 인덱스를 알수있다.
import numpy as np
array_1 = np.array([1,2,3,7,8,9,4,5,6,10,11,9],int)
np.argsort(array_1)위와같이 np.argsort(배열명) 형식으로 argsort함수를 사용할수있다.
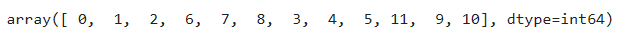
위 코드의 출력결과이다. value 값 크기순대로 인덱스가 부여된것을 확인할수있다.
이제 배열내 최솟값, 최댓값의 인덱스 반환을 해보자. 알고리즘 문제를 풀때 굉장히 많이쓰이는 기능인데 넘파이에선 이것또한 내장함수로 넣어놨다.
import numpy as np
array_1 = np.array([1,2,3,7,8,9,4,5,6,10,11,9],int)
print(np.argmax(array_1))
print(np.argmin(array_1))어차피 min, max 형식은 동일하므로 print문을 이용해 두개 결과를 동시에 출력해보자. 최솟값 인덱스는 np.argmin(배열명)으로, 최댓값 인덱스는 np.argmax(배열명)으로 출력할수있다. 위의 argsort와도 형식이 같다. 여기서 arg는 접두사로 argument(인자)를 의미하는게 아니라 index를 의미한다. 그러기에 위의 정렬과 최댓최솟값도 다 인덱스를 반환하는것이다.
이정도면 넘파이의 주요 기능들은 어느정도 정리가 된것같다. 추가로 더 필요한것이 있다면 또 다른글에 정리해보겠다...
'💻 Computer Science > python & module 🐤' 카테고리의 다른 글
| [python] numpy(넘파이) 배열생성, 구조 변경, 속성 - 사용가이드 1편 (0) | 2024.05.12 |
|---|---|
| 명령프롬프트를 이용해 네이버 멋지게 켜기 (0) | 2024.02.06 |
| [python] IndexError: list index out of range (0) | 2024.01.27 |

